Contents
Kerasとは
Kerasはディープラーニングのプログラムを比較的簡単に実装するためのフレームワークです.Kerasの他にも,Chainerなどの似たフレームワークもいくつかあります.
そもそも,機械学習を行うためのライブラリとしてGoogleが提供しているTensorFlowというライブラリがあるのですが,機能が豊富すぎてこれからディープラーニングを始める人にとっては少し複雑すぎるという欠点があります.ですが,Kerasを使うとTensorFlowを簡単に動かすことができます.実際にどのように使うのかは,この記事で追って説明します.KerasやTensorFrowのインストールはちょっと面倒くさいのでGoogle Colabを使うとすぐにKerasが使えます.
今回は,Kerasを用いてニューラルネットワークを構築して学習を行います.
MNISTとは
今回は,MNIST(エムニスト)というデータセットを使います.MNISTは手書きの0~9の数字が書かれた28×28画素の白黒画像データで,60000枚のトレーニングデータと10000枚のテストデータが用意されています.画像それぞれに,手書きの数字に対応した正解ラベルが割り振られています.以下の画像はMNISTの中身の一例です.
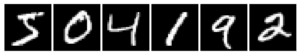
サンプルコード
以下,サンプルコードです.前回のニューラルネットワークは非常に簡素なものでしたが,今回はもう少ししっかりしたものを構築するので,ちょっと長い解説になると思います.また,このページの下部にコード全文を掲載します.
|
1 2 |
import keras from keras.datasets import mnist |
まずはKerasのインポートです.そして,MNISTのデータセットもインポートします.Kerasには元からMNISTのデータセットが用意されています.
|
1 |
(x_train, y_train), (x_test, y_test) = mnist.load_data() |
そしてこれまでと同様,MNISTのデータをトレーニングデータとテストデータに分割します.元から6:1に分けられているので,ここで数値を指定しなくても勝手に分けられます.x_で始まるのが画像データで,y_で始まるのがそれに対応する0~9のラベルです.
次に画像データをニューラルネットワークに入力出来る形にしていきます.トレーニングデータとテストデータそれぞれに同様の処理を施しています.
|
1 2 |
x_train = x_train.reshape(60000, 784) x_test = x_test.reshape(10000, 784) |
上のコードでは,28×28の2次元配列を,784×1の1次元配列に変換しています.
|
1 2 |
x_train = x_train.astype('float32') x_test = x_test.astype('float32') |
また,配列内の数字が整数型では扱えないので, int型をfloat32型に変換しています.
|
1 2 |
x_train /= 255 x_test /= 255 |
白黒画像なので各画素には0~255の値が入っていますが,これを全て0.0~1.0に変換しています.
次にラベルデータも変換します.Kerasの to_categorical関数を使って,整数値を2値クラスの配列に変換します.例えば2という値は[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]という配列に変換されます.
|
1 2 |
y_train = keras.utils.to_categorical(y_train, 10) y_test = keras.utils.to_categorical(y_test, 10) |
また,今回は0~9までの10種類のクラス分類を行うのでクラス数として10を指定します.
さて,データの準備が一通り終わったのでニューラルネットワークモデルを構築します.
|
1 2 |
from keras.models import Sequential from keras.layers import Dense, Dropout |
まずはKerasのSequentialモデルというものをインポートします.これはニューラルネットワークの各層を格納する箱のようなものです.この箱の中で層を積み重ねていくイメージです.
その次にインポートしているDenseとDropoutは層の種類です.前回用いたニューラルネットワークでは,入力層を除いてどの層のニューロンもすべて,手前の層の全てのニューロンから値を受け取っていました.このような層を全結合層といいます.Denseレイヤは,この全結合層のことを指します.
しかし,全結合層だけで構築されたニューラルネットワークは過学習に陥りやすくなってしまいます.そこで,学習の際に層の中の一部のニューロンの入出力を行わない(行わないと言っても実際には存在するので入出力を0にする)ことで汎化性能を高め過学習を抑制します.学習のたびに,対象とするニューロンはランダムに選択されます.これをドロップアウトといい,KerasではDropoutレイヤを設けることで直前のDense層においてDropoutを行うことができます.
|
1 2 3 4 5 6 |
model = Sequential() model.add(Dense(512, activation='relu', input_shape=(784,))) model.add(Dropout(0.2)) model.add(Dense(512, activation='relu')) model.add(Dropout(0.2)) model.add(Dense(10, activation='softmax')) |
今回作ったニューラルネットワークモデルは上記のような形をしています.ひとつずつ確認しましょう.
(1行目)Sequentialモデルを定義します.この中で層を積み木のように重ねていきます.
(2行目)今回は784ピクセル分のデータを入力とするので,入力層のニューロンは784個です.これは,input_shape=(784,)として定義しています.この入力層の次の層が,ニューロン数512の全結合層になっています.全結合層の活性化関数はReLU関数を指定しています.
(3行目)続いて,Dropoutレイヤを設けることで,直前の全結合層においてドロップアウトを行います.今回は512個のニューロンのうち,常に2割をランダムにドロップアウトさせます.
(4行目)そしてもう一層,ニューロン数512個の全結合層を設けます.
(5行目)その全結合層においても,常に2割をドロップアウトさせます.
(6行目)最後の全結合層(出力層)のニューロン数は10個です.これはクラス分類数が10個だからです.また,活性化関数としてsoftmax関数を用いています.関数の詳細な説明は省きますが,分類問題の出力層でsoftmax関数を用いることで,出力結果を各クラスの確率として表すことができます.たとえば,入力画像として2の画像を入力したとき,出力結果が
[0.01, 0.01, 0.73, 0.08, 0.01, 0.02, 0.03, 0.01, 0.09, 0.01]
だったとします.正解値は
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
なので,ここから誤差が小さくなるように重みが修正されます.なお,この出力結果の例では73%の確率で2であると判定しているので,誤差はあれどもとりあえず正解できているといえます.
以上でモデルの形は設定できました.コードを見るとどんな形のモデルかひと目で分かるのがKerasの良いところです.
ここで,学習を始める前に,どのような学習処理を行なうかを設定する必要があります.
この設定をすることをKerasではコンパイルといっています.
|
1 2 3 4 |
from keras.optimizers import RMSprop model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) |
学習用データと出力データの誤差を関数の形に表し(損失関数)、これを最小化させることを最適化といいます.RMSpropはそのための最適化アルゴリズムの一つです.他にも選択肢はありますが,今回はこれを使いましょう.ということでこれをインポートしています.
最小化させる損失関数として,categorical_crossentropyを設定しています.これはクロスエントロピーで,今回のような多クラス分類ではよく用いられます.
そしてmetricsは評価関数で,これはモデルの学習には直接寄与しませんが,モデルの性能を表す指標です.今回はモデルの性能として判定精度を出すことで性能の良し悪しを示そうというわけです.
それでは,これまでに構築したモデルを用いて学習を開始します.
|
1 2 3 4 5 |
history = model.fit(x_train, y_train, #トレーニングデータ batch_size=100, #バッチサイズの指定 epochs=20, #エポック数の指定 verbose=1, #ログ出力の指定. validation_data=(x_test, y_test)) #テストデータ |
学習は筋トレのように一度ではなく何度も繰り返すことで汎化性能が高まります.(やりすぎると過学習になりますが…)この繰り返す回数をエポックといい,epochsとして定義しています.
1 回の学習で計算するデータの数のことをバッチサイズといい,トレーニングデータの中からランダムにデータが選択されて学習に使われます. batch_sizeとして定義しています.
1エポックの中では,指定したバッチサイズの学習をバッチ回数分行います.バッチ回数は通常,トレーニングデータをバッチサイズで割った数の切り上げになります.今回の場合はトレーニングデータが60000あるので,バッチ回数は600です.これをエポックの数だけ繰り返して学習させるわけです.
筋トレでいうと,腕立て100回の600セットを20日間行うみたいなものです.
また,verbose=1としておくことで,学習過程のログが出力されます.
最後に学習とその結果の精度を表示するために,以下のコードを入力します.
|
1 2 3 |
score = model.evaluate(x_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) |
結果は以下のようになりました.
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
60000/60000 [==============================] – 12s 194us/step – loss: 0.2374 – acc: 0.9271 – val_loss: 0.1055 – val_acc: 0.9687
~(省略)~
Epoch 20/20
60000/60000 [==============================] – 12s 205us/step – loss: 0.0256 – acc: 0.9942 – val_loss: 0.1299 – val_acc: 0.9814
Test loss: 0.12989266594767915
Test accuracy: 0.9814
エポックが進む毎に少しずつ誤差が低下して精度は上がり,最終的には精度98%まで上がっています.
また,上の出力結果はGPUを使わずノートPCで学習を行った結果ですが,1エポックあたり12秒ほどで処理できています.これくらいならまだ許せる範疇ですが,層構造が深くなったり,入力データが大きくなったりするとGPUを使わないと正直厳しいです.
自分が用意した画像で簡単なテスト
せっかくなので,自分の用意したデータできちんと判定してくれるかテストしましょう.以下のような28×28ピクセルの画像を作ってみました.なお,ファイル名はtest3.pngとしました.
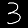
明らかに我々の目には【3】に見えますが,正しく判定してくれるか試してみます.
今回は画像の読み込みを行うので,Google Colabで行う場合と自前の環境で行う場合はコードが若干異なります.まずはGoogle Colabで行う場合のコードから説明します.
Google Colabで行う場合
Google Colabで行う場合,ローカルのファイルに直接アクセスすることは出来ません.ファイルをGoogle Driveにアップすれば読み込むこともできるのですが,今回はファイルをGoogle Colabに直接アップロードするやり方でやってみましょう.
|
1 2 |
from google.colab import files uploaded = files.upload() |
上のコードを実行すると,ファイルの選択を行うことができます.ここで,アップロードしたい画像を選択してください.選択すると,以下のような,アップロードが完了した旨を示す文が出てくると思います.
test3.png(image/png) – 311 bytes, last modified: 2018/9/22 – 100% done
Saving test3.png to test3.png
これでGoogle Colabへのファイルアップロードは完了したので,判定用のコードを入力します.
|
1 |
from keras.preprocessing.image import img_to_array, load_img |
load_imgで画像の読み込み,img_to_arrayで読み込んだ画像を配列に変換できます.
|
1 2 |
test_img = load_img('./test3.png', grayscale=True, target_size=(28,28)) test_img_array = img_to_array(test_img) |
今回用いる画像はグレースケールとして読み込まなければならないので,grayscale=Trueを指定しておきます.
|
1 2 3 |
test_data = test_img_array.reshape(1, 784) test_data = test_data.astype('float32') test_data /= 255 |
学習の際に行ったのと同様,配列を28×28から784×1に変換し,すべて0~1の数字に変換します.
|
1 |
print(model.predict_classes(test_data)) |
predict_classesで結果を出力することができます.結果は以下のようになりました.
3
きちんと3であると認識してくれているようです.
自前の環境で行う場合
Google Colabを使わず,自前の環境で行う場合はもう少し簡単になります.Google Colabにファイルをアップロードするために入力した,以下のコードは不要になります.
|
1 2 |
from google.colab import files uploaded = files.upload() |
上のコードは入力せず,あとはGoogle Colabで行ったのと全く同じコードを入力します.このとき,読み込むファイルは実行するコードと同じディレクトリに置いておいてください.別のところにファイルを置いておく場合は,‘./test3.png’の部分を適宜ファイルが置いてある場所に書き換えてください.
コード全文(Kerasを用いたニューラルネットワーク)
今回紹介したコード全文を以下に示します.関数などの呼び出し文はコードの先頭にまとめています.
学習・評価コード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout from keras.optimizers import RMSprop (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape(60000, 784) x_test = x_test.reshape(10000, 784) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 y_train = keras.utils.to_categorical(y_train, 10) y_test = keras.utils.to_categorical(y_test, 10) model = Sequential() model.add(Dense(512, activation='relu', input_shape=(784,))) model.add(Dropout(0.2)) model.add(Dense(512, activation='relu')) model.add(Dropout(0.2)) model.add(Dense(10, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) history = model.fit(x_train, y_train, #トレーニングデータ batch_size=100, #バッチサイズの指定 epochs=20, #エポック数の指定 verbose=1, #ログ出力の指定. validation_data=(x_test, y_test)) #テストデータ score = model.evaluate(x_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) |
自分の画像でテスト
|
1 2 |
from google.colab import files uploaded = files.upload() |
※Google Colabを用いる場合のみ上記のコードを追加してファイルのアップロードが必要
|
1 2 3 4 5 6 7 8 9 10 |
from keras.preprocessing.image import img_to_array, load_img test_img = load_img('./test3.png', grayscale=True, target_size=(28,28)) test_img_array = img_to_array(test_img) test_data = test_img_array.reshape(1, 784) test_data = test_data.astype('float32') test_data /= 255 print(model.predict_classes(test_data)) |