Contents
キャプション生成
今回は,画像を入力して,その画像の内容を説明する文章を出力するディープラーニングモデルについて解説します.これまでとは違って,かなり長い解説になると思います.
文章を生成する場合,それまでの単語あるいは文章から,次の単語を出力することを繰り返し行う必要があります.そこで,文章生成などのタスクでは時系列データを取り扱うことの出来るRNN(リカレントニューラルネットワーク)が一般的に用いられます.
RNNは,それまでに計算された情報を保持し,次の計算に用いることができます.そして,次々と単語を出力して文章を生成した結果,累積されていった損失から,各出力過程の重みを調整します.このようにすることで,文章などの連続したデータの学習が可能になります.
今回は,RNNの一種である,LSTM(Long short-term memory)を用いてキャプション生成を行います.LSTMはRNNよりも複雑な構造ですが,Kerasで実装する場合は,これまでに行ったディープラーニングモデルと同様にモデルの途中にLSTMレイヤを挟み込むだけなので,あまり細かい中身を意識しなくても容易に実装することが可能です.
データセットの準備
キャプション生成用のデータセットとして,ここではMS-COCOを用います.MS-COCOには元々英語のキャプションが付いていますが,ありがたいことに日本語のキャプションも用意してくださった方々がいるので,今回は日本語キャプションで学習と生成を行いましょう.日本語のキャプションデータは,STAIR Lab / ステアラボ千葉工業大学人工知能・ソフトウェア技術研究センターが作成・公開しています.
このキャプションデータは,MS-COCOの16万枚の画像に各画像5文ずつ,計80万文が用意されています.ですが,今回は雰囲気を掴むために,バリデーション用のデータである『stair_captions_v1.2_val_tokenized.json』のさらに一部,2000枚(1万文)を用いて学習および評価,テストを行いましょう.
MS-COCOおよびSTAIR Labによるキャプションデータのダウンロードは,こちらのリンクから可能です.MS-COCOのデータは,『2014 Val images [41K/6GB]』を選んでください.(http://cocodataset.org/#download)(http://captions.stair.center/)
また,このキャプションデータはJSON形式で記述されていることから,少々見づらく,さらに今回ここで用いるにあたっては余計なデータも多く含まれているので,まず最初により使いやすい形に成形したいと思います.そのためのコードを以下に示します.
|
1 2 3 4 5 6 |
import json import pandas as pd import numpy as np f = open("stair_captions_v1.2_val_tokenized.json", 'r', encoding='utf-8') json_data = json.load(f) |
最初に,必要なモジュールをインポートし,JSONファイルをインポートして読み込みます.日本語を扱う都合上,文字コードに関するエラーが出る可能性は往々にしてあるので,万一出てしまったら随時対応して下さい.
|
1 2 3 4 5 |
id_file = {} for i in range(len(json_data["images"])): file_name = json_data["images"][i]["file_name"] id = json_data["images"][i]["id"] id_file[id] = file_name |
続いて,このJSONファイルにおいては画像のファイル名がIDに紐づけられていることから,画像のファイル名とIDを対応させたディクショナリを作っておきます.
|
1 2 3 4 5 6 7 8 9 |
annotations_size = len(json_data["annotations"]) df = pd.DataFrame(data = np.zeros((annotations_size,2))) for j in range(annotations_size): image_id = json_data["annotations"][j]['image_id'] file_name = id_file[image_id] caption = json_data["annotations"][j]["tokenized_caption"] df.loc[j, 0] = file_name df.loc[j, 1] = caption |
続いて,総キャプション数に合わせたpandasのデータフレームを作り,データフレームに各画像とキャプションを対応させていきます.(どうせ2000枚しか使わないのに全画像を処理するのは無駄感がありますが,大した量ではないのでザザっとやっちゃってます)
|
1 2 3 4 5 6 |
data_size = 10000 df.sort_values(0, inplace=True) df= df.reset_index(drop=True) df= df.loc[:data_size-1] df.to_csv("caption.txt", sep=" ", header=False, index=False, encoding='utf-8') |
最後に,データフレームの上から10000行をtxtファイルとして出力します.生成されたtxtファイルの,上から6行分が以下のようになっています.
COCO_val2014_000000000042.jpg “白い 靴 や 赤 や 黒 の 草履 が 乱雑 に 置か れ た 棚”
COCO_val2014_000000000042.jpg “玄関 の かご の 中 に 靴 と 一緒 に 紛れこん で いる トイ プードル”
COCO_val2014_000000000042.jpg “ケージ に 置か れ た 靴 に 犬 が 頭 を のせ て 寝 て いる”
COCO_val2014_000000000042.jpg “かご の 中 に 靴 が 入れ られ て いる”
COCO_val2014_000000000042.jpg “スニーカー や サンダル が 入っ た バスケット に 犬 が 寝 て いる”
COCO_val2014_000000000073.jpg “アスファルト の 上 に 停め て ある 黒い バイク”
このように,画像1つにキャプションが5つ,画像名[半角スペース]”説明文”の形で指定されていることが確認できます.ちなみに,COCO_val2014_000000000042.jpgの画像は以下のような画像です.(気づいたかもしれませんが,本記事のサムネイルのAIはこの正解データと同じ文をドンピシャで想像しているので,ちょっとやりすぎですね,こんな風に文を出力してくれるといいんですが.)

また,説明文を見ると分かると思いますが,単語ごとに文章が区切られています.これは,単語ごとに学習・出力を行う必要があるからです.英文ではそもそも各単語間にスペースがあるため心配ないのですが,日本語でキャプション生成を行う場合はこのような配慮(形態素解析)が必要です.なお,STAIR Labが用意したキャプションの形態素解析は,形態素解析を自動で行うツールであるMeCab(めかぶ)を用いて行われているとのことです.
そして,今回用いるデータセットについて,トレーニング用に8割(1600枚),バリデーション用に約2割(399枚),最後の1枚がテスト用,になるように事前に指定しておきます.また同時に,今回使う2万枚の画像も,ダウンロードしたCOCOデータセットが入っているフォルダ(val2014)から,新しい他のフォルダにコピーしておきます.以下にそのためのコードを示します.
|
1 2 3 4 5 6 7 8 |
# -*- coding: utf-8 -*- import pandas as pd import os import shutil file = open('path/to/caption.txt', 'r', encoding='utf-8') caption_data = file.read() file.close() |
最初に,必要なモジュールをインポートし,先ほど出力したtxtファイルを読み込みます.
|
1 2 3 4 5 6 7 8 |
image_list = [] for line in caption_data.split('\n'): tokens = line.split() if len(line) < 2: continue image_id, image_desc = tokens[0], tokens[1:] if image_id not in image_list: image_list.append(image_id) |
続いて,txtファイルに書かれていた画像名の部分だけをリストに格納していきます.
|
1 2 3 4 |
os.mkdir('path/to/photo_data') for list in image_list[:-1]: shutil.copy('path/to/val2014/{}'.format(list), 'path/to/photo_data') |
そしてまずは,トレーニング画像とバリデーション画像をコピーして入れておくフォルダ「photo_data」を作成し,COCOデータセットのフォルダ「val2014」から,最後の1枚以外を「photo_data」にコピーします.適宜自分の環境に合わせてパスを設定してください.(参照ディレクトリ内に同じ名前のフォルダが既に存在するとエラーが出ます.)
|
1 2 |
os.mkdir('path/to/test_data') shutil.copy('path/to/val2014/{}'.format(image_list[-1]), 'path/to/test_data') |
同じ要領で,最後の1枚だけを新しく作ったフォルダ「test_data」にコピーします.
|
1 2 3 4 5 |
train_data = pd.Series(image_list[:1600]) val_data = pd.Series(image_list[1600:1999]) train_data.to_csv("train.txt", header=False, index=False) val_data.to_csv("val.txt", header=False, index=False) |
最後にデータをトレーニングデータとバリデーションデータに分けて,train.txt,val.txtの2つのファイルを新たに生成します.
なお,tarin.txtの上から3行分は,以下のようになっています.
COCO_val2014_000000000042.jpg
COCO_val2014_000000000073.jpg
COCO_val2014_000000000074.jpg
このように,使用する画像の名前が羅列してあります.
以上でデータセットの準備は完了です.以上のような形式でデータを用意さえすれば,今回解説するコードでキャプション生成が可能です.ですから,自前のデータをExcelに入力してtxt形式で出力・保存するなど,自分にあった形でデータセットを構築して構いません.
それでは,本題のキャプション生成モデルの作成について,以下に説明します.
サンプルコード
以下,サンプルコードです.
|
1 2 3 4 5 |
# -*- coding: utf-8 -*- image_directory = 'path/to/photo_data'#画像データのパスを指定すること caption_data = 'path/to/caption.txt'#キャプションデータのパスを指定すること train_data = 'path/to/train.txt'#トレーニングデータのパスを指定すること val_data = 'path/to/val.txt'#バリデーションデータのパスを指定すること |
まず,全てのデータのパスを指定しておきます.今後,適宜呼び出します.
画像の特徴抽出
画像からキャプション生成を行うにあたっては,各画像の特徴ベクトルに対応してキャプションを学習・生成します.そのために,まず最初にCNNに画像を通して,最終層でクラス分類される手前で出力される特徴量を抽出します.そのためのコードが以下になります.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
from os import listdir from pickle import dump from keras.applications.vgg16 import VGG16,preprocess_input from keras.preprocessing.image import load_img,img_to_array from keras.models import Model # 指定したディレクトリ内の各写真から特徴を抽出する関数 def extract_features(directory): model = VGG16() model.layers.pop() model = Model(inputs=model.inputs, outputs=model.layers[-1].output) features = dict() #特徴を格納するためのディクショナリ for name in listdir(directory): filename = directory + '/' + name #ファイルから画像を読み込む image = load_img(filename, target_size=(224, 224)) #VGG16用に224×224に成形 image = img_to_array(image) #numpy配列に変換 image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2])) #モデルに読み込ませるために成形 image = preprocess_input(image) #VGGモデルに画像を読み込ませる feature = model.predict(image, verbose=0) #特徴抽出 image_id = name.split('.')[0] #画像の名前を取得 features[image_id] = feature #画像の名前と特徴を紐付け return features #特徴抽出 features = extract_features(image_directory) #特徴をpklファイルとして保存 dump(features, open('features.pkl', 'wb')) |
今回は特徴抽出用のCNNモデルとして,VGG16を用いています.VGG16の最終層を取り払い,画像をVGG16に入力できる形に成形し,モデルに通して抽出した特徴と画像名を紐づけて,全ての画像のデータをpklファイルとして保存します.今後,文章の学習・生成をする際には,これらの特徴量を初期入力とします.なお,このようにすると学習時にVGG16モデルそのものの学習は行われませんが,学習できるように設定してもあまり効果的でないことが知られています.
キャプションの読み込みと成形
|
1 2 3 4 5 6 7 8 9 |
#ファイルを読み込む関数 def load_doc(filename): file = open(filename, 'r', encoding='utf-8') text = file.read() file.close() return text #キャプションデータの読み込み doc = load_doc(caption_data) |
まずはファイルの読み込みのための関数を定義し,全てのキャプションを読み込みます.この関数は今後も適宜使用します.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#キャプションと画像名を紐づけする関数 def load_descriptions(doc): mapping = dict() for line in doc.split('\n'): tokens = line.split() if len(line) < 2: continue image_id, image_desc = tokens[0], tokens[1:] #最初の単語を画像名、残り全てをキャプションとして読み込む image_id = image_id.split('.')[0] #ピリオドより手前を画像名とする image_desc = ' '.join(image_desc) #キャプションの単語を文字列に戻す if image_id not in mapping: #その画像名が一つ目ならリストを作成 mapping[image_id] = list() mapping[image_id].append(image_desc) #画像名にキャプションを紐づけてディクショナリに格納 return mapping #キャプションと画像の紐づけ descriptions = load_descriptions(doc) |
つづいてディクショナリを定義し,各画像とキャプションを紐付けています.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import string #余計な記号を除去する関数 def clean_descriptions(descriptions): table = str.maketrans('', '', string.punctuation)#記号をリストアップ for key, desc_list in descriptions.items(): for i in range(len(desc_list)): desc = desc_list[i] desc = desc.split() #キャプションを単語に区切る desc = [w.translate(table) for w in desc] #記号を消去 desc_list[i] = ' '.join(desc) #キャプションの単語を文字列に戻す #余計な記号を除去する clean_descriptions(descriptions) |
今回用いるキャプションの中には,文頭文末のダブルクォーテーションなど,不要な記号が含まれています.これらをここで除去します.string.punctuationで[!”#$%&'()*+,-./:;<=>?@[\]^_`{|}~]←これらをまとめて指定可能です.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#語彙が縮小されたキャプションを保存する関数 def save_descriptions(descriptions, filename): lines = list() for key, desc_list in descriptions.items(): for desc in desc_list: lines.append(key + ' ' + desc) data = '\n'.join(lines) file = open(filename, 'w', encoding='utf-8') file.write(data) file.close() #語彙が縮小されたキャプションをtxtファイルとして保存 save_descriptions(descriptions, 'descriptions.txt') #画像数のチェック print('Loaded: %d ' % len(descriptions)) |
語彙が縮小されたキャプションは,descriptions.txtとして新たに保存されます.
最後に,画像数のチェックを行っています.今回は2000枚あるので,2000と出力されると思います.
トレーニングデータとバリデーションデータの準備
ここでは,トレーニングデータとバリデーションデータを,いくつかの段階を踏まえて,学習・評価に使える形に成形します.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#データセットの画像名のリストを作成する関数 def load_set(filename): doc = load_doc(filename) dataset = list() for line in doc.split('\n'): if len(line) < 1: continue identifier = line.split('.')[0] dataset.append(identifier) return set(dataset) #トレーニングデータの画像名のリスト作成 train = load_set(train_data) #バリデーションデータの画像名のリスト作成 val = load_set(val_data) |
まず,上記の関数を使って,トレーニングデータとバリデーションデータの画像名が格納されたリストを作成しています.なお,引数に用いているtrain_dataとval_dataは,本サンプルコードの一番最初に指定したものです.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#画像名とキャプションを紐付けたディクショナリを作成する関数 def load_clean_descriptions(filename, dataset):#引数datasetはtrainとかvalとか doc = load_doc(filename) descriptions = dict() for line in doc.split('\n'):#一行ずつ読み込む tokens = line.split() #空白で区切る image_id, image_desc = tokens[0], tokens[1:] #最初の単語を画像名、残り全てをキャプションとして読み込む if image_id in dataset: #画像名がデータセット中に指定されていれば以下を実行 if image_id not in descriptions: #その画像名が一つ目ならリストを作成 descriptions[image_id] = list() desc = 'startseq ' + ' '.join(image_desc) + ' endseq' #キャプションを開始語と終了語で囲む descriptions[image_id].append(desc) #ディクショナリに格納 return descriptions #トレーニングデータのキャプションと画像名を紐付ける train_descriptions = load_clean_descriptions('descriptions.txt', train) #バリデーションデータのキャプションと画像名を紐付ける val_descriptions = load_clean_descriptions('descriptions.txt', val) |
上記の関数の引数filenameには先ほど作成したファイルdescriptions.txtを指定し,引数datasetには先ほど作成したリストtrainおよびリストvalを指定します.この関数を使って,トレーニングデータとバリデーションデータの画像名とキャプションが紐付けられたディクショナリを作成しています.
ここで,各キャプションを何らかの開始語と終了語で挟みます(ここではstartseqおよびendseqとしています).文章生成の際には,画像と開始語を入力として与えて,そこから続く単語を次々と予測し,終了後が出力されたら文章生成を打ち止めます.
|
1 2 3 4 5 6 7 8 9 10 11 |
from pickle import load #画像の特徴量を読み込む関数 def load_photo_features(filename, dataset): all_features = load(open(filename, 'rb')) features = {k: all_features[k] for k in dataset}#画像名と特徴量を紐づけてディクショナリに格納 return features #トレーニングデータの特徴量と画像名を紐付ける train_features = load_photo_features('features.pkl', train) #バリデーションデータの特徴量と画像名を紐付ける val_features = load_photo_features('features.pkl', val) |
上記の関数の引数filenameには最初に作成したファイルfeatures.pklを指定し,引数datasetには先ほど作成したリストtrainおよびリストvalを指定します.この関数を使って,トレーニングデータとバリデーションデータの画像名と特徴量が紐付けられたディクショナリを作成しています.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from keras.preprocessing.text import Tokenizer #キャプションのディクショナリをリストにする関数 def to_lines(descriptions): all_desc = list() for key in descriptions.keys(): [all_desc.append(d) for d in descriptions[key]] return all_desc #キャプションをKerasのTokenizerで扱うために変換する def create_tokenizer(descriptions): lines = to_lines(descriptions) tokenizer = Tokenizer() tokenizer.fit_on_texts(lines) return tokenizer #tokenizerを準備する tokenizer = create_tokenizer(train_descriptions) vocab_size = len(tokenizer.word_index) + 1 |
機械学習において文字列を扱うためには、単語をベクトル表現する必要があります.単語をベクトル表現することで,各単語間の関係性を学習することが可能になります.KerasにはTokenizerという便利なものがあり,これを使うことで単語をベクトル配列に変換することができます.ここではまず最初にキャプションのリストを生成し,これをもとにベクトル化します.なお,キャプションのリストにはtrain_descriptionsを指定するので,トレーニングデータのキャプションに含まれている単語のみベクトル化されます.
|
1 2 3 4 5 6 7 |
#最も多くの単語を含むキャプションの長さを計算する関数 def max_length(descriptions): lines = to_lines(descriptions) return max(len(d.split()) for d in lines) #最大シーケンス長を計算する max_length = max_length(train_descriptions) |
次に,トレーニングデータの文章のうち,最大の文の長さを取得します.これは,モデルの入力層のノード数は一定にしなくてはいけないので,それをトレーニングデータの文の最大長に合わせるためです.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
from keras.preprocessing.sequence import pad_sequences from keras.utils import to_categorical from numpy import array #画像と出力単語を紐づける関数 def create_sequences(tokenizer, max_length, descriptions, photos): X1, X2, y = list(), list(), list()#X1が入力画像、X2が入力語、yがX1とX2に対応する出力語 #各画像名でループ for key, desc_list in descriptions.items(): #各画像のキャプションでループ for desc in desc_list: #シーケンスをエンコードする seq = tokenizer.texts_to_sequences([desc])[0] #1つのシーケンスを複数のX、Yペアに分割する for i in range(1, len(seq)): #入力と出力のペアに分割する in_seq, out_seq = seq[:i], seq[i] #行列のサイズを最大の単語数に合わせる in_seq = pad_sequences([in_seq], maxlen=max_length)[0] #出力シーケンス out_seq = to_categorical([out_seq], num_classes=vocab_size)[0] #全てをarrayに格納 X1.append(photos[key][0]) X2.append(in_seq) y.append(out_seq) return array(X1), array(X2), array(y) #トレーニングデータの入力画像、入力語、出力語を紐付ける X1train, X2train, ytrain = create_sequences(tokenizer, max_length, train_descriptions, train_features) #バリデーションデータの入力画像、入力語、出力語を紐付ける X1val, X2val, yval = create_sequences(tokenizer, max_length, val_descriptions, val_features) |
そして最後に,キャプションデータ,画像データを紐づけ,モデルに入力するためのデータセットとします.ここでは,画像とそれに対応する入力語,入力語から予測されるべき出力語を,そのすべてのパターンにおいて設定します.以上でモデルに入力できる形のデータの準備は完了です.
モデルの構築
さて,ここからやっとメインのモデル構築です.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from keras.layers import Input,Dense,LSTM,Embedding,Dropout from keras.layers.merge import add #モデルを定義する関数 def define_model(vocab_size, max_length): #画像の特徴を入力するレイヤ inputs1 = Input(shape=(4096,)) fe1 = Dropout(0.5)(inputs1) fe2 = Dense(256, activation='relu')(fe1) #文章を入力するレイヤ inputs2 = Input(shape=(max_length,)) se1 = Embedding(vocab_size, 256, mask_zero=True)(inputs2) se2 = Dropout(0.5)(se1) se3 = LSTM(256)(se2) #上の二つの出力を統合する部分 decoder1 = add([fe2, se3]) decoder2 = Dense(256, activation='relu')(decoder1) outputs = Dense(vocab_size, activation='softmax')(decoder2) #モデルの定義.二つを入力にとって一つを出力する形になる model = Model(inputs=[inputs1, inputs2], outputs=outputs) model.compile(loss='categorical_crossentropy', optimizer='adam') return model |
今までのモデルは単一のレイヤが一列に積み重なっていただけでしたが,今回のモデルは以下のような構造になっています.
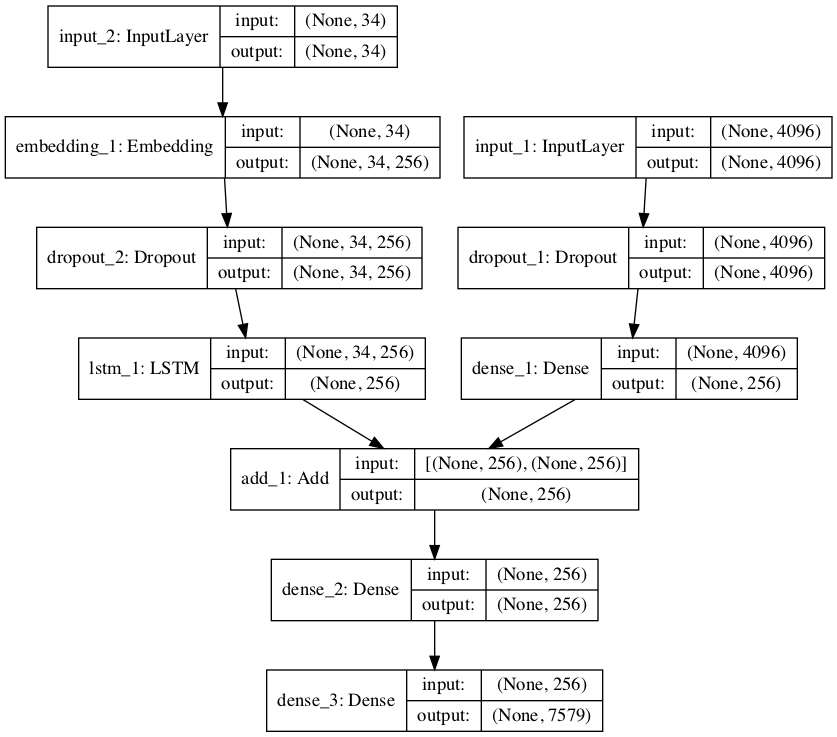
この構造を見て目につくように,このモデルは入力を2つとって1つの出力としています.
すなわち,input1から画像(の特徴量),input2から文章を入力し,outputで続く単語を出力します.また,時系列データを処理するLSTMレイヤは,input2からなる層に配置されていることが確認できます.
input1の入力ノード4096は,VGG16の出力した特徴量を受け取ることからです.また,input2の入力ノード34は,トレーニングデータにおける文章の最大長です.input2には,それまで生成された文章が入力として与えられるのですが,その文章を最大長に合わせてパディングして入力として与えます.outputの7579は,出力されうる単語数を示しています.当たり前ですが,学習していない語彙は出力することはできません.(なお,34や7579というのは一例で,今回のデータセットでは,また違った数値になっていると思います.)
では,定義したモデルを使って学習を行います.
|
1 2 3 4 5 6 7 8 9 |
from keras.callbacks import ModelCheckpoint #モデルの定義 model = define_model(vocab_size, max_length) #コールバックを定義する filepath = 'model-ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5' checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='min') #学習 model.fit([X1train, X2train], ytrain, epochs=10, verbose=2, callbacks=[checkpoint], validation_data=([X1val, X2val], yval)) |
今回はKerasのコールバックを定義しています.エポックごとにval_lossをモニターすることで,val_lossがそれまでの最小値だったらそのときの重みのモデルをファイルとして保存します.
テストする際や,新規に画像のキャプションを生成する際は,最後に出力されたモデルを読み込み実施するだけで良いです.データ量が多いので,実行には少し時間がかかると思います.上記のコードを実行すると,以下のような結果が出力されると思います.
Train on 108400 samples, validate on 25833 samples
Epoch 1/10
– 188s – loss: 4.0848 – val_loss: 3.4455
Epoch 00001: val_loss improved from inf to 3.44553, saving model to model-ep001-loss4.085-val_loss3.446.h5
~省略~
Epoch 00005: val_loss improved from 3.13871 to 3.13543, saving model to model-ep005-loss2.581-val_loss3.135.h5
~省略~
Epoch 10/10
– 184s – loss: 2.2064 – val_loss: 3.3320
Epoch 00010: val_loss did not improve from 3.13543
エポックのval_lossが最小の場合は新しくモデルを保存しているのが分かります.それでは,テストデータの1つを使って実際に文章を生成してみます.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#ディレクトリ内の写真から特徴を抽出する def extract_features_from_image(filename): model = VGG16() model.layers.pop() model = Model(inputs=model.inputs, outputs=model.layers[-1].output) image = load_img(filename, target_size=(224, 224)) image = img_to_array(image) image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2])) image = preprocess_input(image) feature = model.predict(image, verbose=0) return feature photo = extract_features_from_image('path/to/test.image')#テスト画像のパスを指定すること |
まず,本サンプルコードで最初に実行した,全ての写真から特徴を抽出する関数を少し書き換え,個別の画像から特徴量を抽出する関数を定義します.この関数を使って,テスト画像の特徴量を抽出します.ここで,テスト画像のパスを指定してください.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
from numpy import argmax from keras.models import load_model #整数を単語に変換する関数 def word_for_id(integer, tokenizer): for word, index in tokenizer.word_index.items(): if index == integer: return word return None #画像からキャプションを生成する関数 def generate_desc(model, tokenizer, photo, max_length): in_text = 'startseq' for i in range(max_length): sequence = tokenizer.texts_to_sequences([in_text])[0] sequence = pad_sequences([sequence], maxlen=max_length) yhat = model.predict([photo,sequence], verbose=0) yhat = argmax(yhat) word = word_for_id(yhat, tokenizer) if word is None: break in_text += ' ' + word if word == 'endseq': break return in_text model = load_model('model-ep005-loss2.581-val_loss3.135.h5')#最後に出力されたモデルを指定する description = generate_desc(model, tokenizer, photo, max_length) print(description) |
続いて,整数を単語に戻す関数を定義します.モデルを学習する際に,各単語は番号に置き換えているので,実際に出力される際にも番号で出力されます.これを,この関数で対応する単語に戻すことができます.
その次に定義しているのが,実際に画像からキャプションを生成する関数です.
yhat = model.predict([photo,sequence], verbose=0)の部分を見ると,画像(の特徴量)とそれまでに生成された文章を入力していることが分かります.なお,一番最初に入力されるのは開始語(この場合はstartseq)です.
結果としては各単語の確率が出力されるのですが,yhat = argmax(yhat)で,最も確率が高い単語を選択します.そして,in_text += ‘ ‘ + wordの部分で,それまでの文章と新たに出力された文章を繋げます.これを,次のループで新たな入力として使います.これを終了語が出力されるまで繰り返します.すなわちここでは,写真と,それまでに生成された文章から,次に来る確率が最も高い単語を繰り返し出力して文章を生成しているということです.
最後に,今回学習によって得られたモデルを変数modelに定義します.上記のコードは一例で,実際には最後に出力されたモデルのパスを入力してください.そして,キャプション生成の関数を実行し,その結果を表示します.以下のような結果が表示されました.(シード値の固定などは行っていないので,人によって答えは少し違うかもしれません.)
startseq 男性 が スキー を し て ジャンプ し て いる endseq
ちなみにテスト画像はこちらでした.

残念ながらこれは間違った文章です.スキーじゃなくてサーフィンだったらそこそこ良かったのですが.とはいえ,日本語として間違っているレベルのおかしな文章ではないですし,モデルを調整するか,データ量を増やすことで,精度向上の期待が持てそうです.
追記
今回のコードは説明を簡単にするために,学習データを小分けにするミニバッチ学習を行っていないので,これよりさらにデータ量を増やすとメモリエラーが発生する可能性があります.(環境によっては,今回のデータ量でもメモリエラーが発生するかもしれません.)ミニバッチ学習の方法をこの記事に追加するとあまりに内容が膨大になるので,次回以降に説明したいと思います.
また,今回の出力では最も確率の高い単語を順次つなげていったので,文章が1文のみ出力されました.とはいえ,場合によっては2文,3文出力すれば,1文では言い表せなかった内容も出力できる可能性があります.こちらについても,次回以降に併せて説明したいと思います.
コード全文
以下に,今回のコード全文を示します.
データの準備
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import json import pandas as pd import numpy as np f = open("stair_captions_v1.2_val_tokenized.json", 'r', encoding='utf-8') json_data = json.load(f) id_file = {} for i in range(len(json_data["images"])): file_name = json_data["images"][i]["file_name"] id = json_data["images"][i]["id"] id_file[id] = file_name annotations_size = len(json_data["annotations"]) df = pd.DataFrame(data = np.zeros((annotations_size,2))) for j in range(annotations_size): image_id = json_data["annotations"][j]['image_id'] file_name = id_file[image_id] caption = json_data["annotations"][j]["tokenized_caption"] df.loc[j, 0] = file_name df.loc[j, 1] = caption data_size = 10000 df.sort_values(0, inplace=True) df= df.reset_index(drop=True) df= df.loc[:data_size-1] df.to_csv("caption.txt", sep=" ", header=False, index=False, encoding='utf-8') |
上のコードは,STAIR Labのデータセットを,扱いやすいように成形するコードです.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# -*- coding: utf-8 -*- import pandas as pd import os import shutil file = open('path/to/caption.txt', 'r', encoding='utf-8') caption_data = file.read() file.close() image_list = [] for line in caption_data.split('\n'): tokens = line.split() if len(line) < 2: continue image_id, image_desc = tokens[0], tokens[1:] if image_id not in image_list: image_list.append(image_id) os.mkdir('path/to/photo_data') for list in image_list[:-1]: shutil.copy('path/to/val2014/{}'.format(list), 'path/to/photo_data') os.mkdir('path/to/test_data') shutil.copy('path/to/val2014/{}'.format(image_list[-1]), 'path/to/test_data') train_data = pd.Series(image_list[:1600]) val_data = pd.Series(image_list[1600:1999]) train_data.to_csv("train.txt", header=False, index=False) val_data.to_csv("val.txt", header=False, index=False) |
上のコードは,成形したキャプションデータをもとに,画像をフォルダ分けして,トレーニングデータとバリデーションデータの画像名を指定したファイルを出力するコードです.
モデル構築
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 |
# -*- coding: utf-8 -*- from os import listdir from pickle import dump from keras.applications.vgg16 import VGG16,preprocess_input from keras.preprocessing.image import load_img,img_to_array from keras.models import Model import string from pickle import load from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences from keras.utils import to_categorical from numpy import array from keras.layers import Input,Dense,LSTM,Embedding,Dropout from keras.layers.merge import add from keras.callbacks import ModelCheckpoint image_directory = 'path/to/photo_data'#画像データのパスを指定すること caption_data = 'path/to/caption.txt'#キャプションデータのパスを指定すること train_data = 'path/to/train.txt'#トレーニングデータのパスを指定すること val_data = 'path/to/val.txt'#バリデーションデータのパスを指定すること # 指定したディレクトリ内の各写真から特徴を抽出する関数 def extract_features(directory): model = VGG16() model.layers.pop() model = Model(inputs=model.inputs, outputs=model.layers[-1].output) features = dict() #特徴を格納するためのディクショナリ for name in listdir(directory): filename = directory + '/' + name #ファイルから画像を読み込む image = load_img(filename, target_size=(224, 224)) #VGG16用に224×224に成形 image = img_to_array(image) #numpy配列に変換 image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2])) #モデルに読み込ませるために成形 image = preprocess_input(image) #VGGモデルに画像を読み込ませる feature = model.predict(image, verbose=0) #特徴抽出 image_id = name.split('.')[0] #画像の名前を取得 features[image_id] = feature #画像の名前と特徴を紐付け return features #特徴抽出 features = extract_features(image_directory) #特徴をpklファイルとして保存 dump(features, open('features.pkl', 'wb')) #ファイルを読み込む関数 def load_doc(filename): file = open(filename, 'r', encoding='utf-8') text = file.read() file.close() return text #キャプションデータの読み込み doc = load_doc(caption_data) #キャプションと画像名を紐づけする関数 def load_descriptions(doc): mapping = dict() for line in doc.split('\n'): tokens = line.split() if len(line) < 2: continue image_id, image_desc = tokens[0], tokens[1:] #最初の単語を画像名、残り全てをキャプションとして読み込む image_id = image_id.split('.')[0] #ピリオドより手前を画像名とする image_desc = ' '.join(image_desc) #キャプションの単語を文字列に戻す if image_id not in mapping: #その画像名が一つ目ならリストを作成 mapping[image_id] = list() mapping[image_id].append(image_desc) #画像名にキャプションを紐づけてディクショナリに格納 return mapping #キャプションと画像の紐づけ descriptions = load_descriptions(doc) #余計な記号を除去する関数 def clean_descriptions(descriptions): table = str.maketrans('', '', string.punctuation)#記号をリストアップ for key, desc_list in descriptions.items(): for i in range(len(desc_list)): desc = desc_list[i] desc = desc.split() #キャプションを単語に区切る desc = [w.translate(table) for w in desc] #記号を消去 desc_list[i] = ' '.join(desc) #キャプションの単語を文字列に戻す #余計な記号を除去する clean_descriptions(descriptions) #語彙が縮小されたキャプションを保存する関数 def save_descriptions(descriptions, filename): lines = list() for key, desc_list in descriptions.items(): for desc in desc_list: lines.append(key + ' ' + desc) data = '\n'.join(lines) file = open(filename, 'w', encoding='utf-8') file.write(data) file.close() #語彙が縮小されたキャプションをtxtファイルとして保存 save_descriptions(descriptions, 'descriptions.txt') #画像数のチェック print('Loaded: %d ' % len(descriptions)) #データセットの画像名のリストを作成する関数 def load_set(filename): doc = load_doc(filename) dataset = list() for line in doc.split('\n'): if len(line) < 1: continue identifier = line.split('.')[0] dataset.append(identifier) return set(dataset) #トレーニングデータの画像名のリスト作成 train = load_set(train_data) #バリデーションデータの画像名のリスト作成 val = load_set(val_data) #画像名とキャプションを紐付けたディクショナリを作成する関数 def load_clean_descriptions(filename, dataset):#引数datasetはtrainとかvalとか doc = load_doc(filename) descriptions = dict() for line in doc.split('\n'):#一行ずつ読み込む tokens = line.split() #空白で区切る image_id, image_desc = tokens[0], tokens[1:] #最初の単語を画像名、残り全てをキャプションとして読み込む if image_id in dataset: #画像名がデータセット中に指定されていれば以下を実行 if image_id not in descriptions: #その画像名が一つ目ならリストを作成 descriptions[image_id] = list() desc = 'startseq ' + ' '.join(image_desc) + ' endseq' #キャプションを開始語と終了語で囲む descriptions[image_id].append(desc) #ディクショナリに格納 return descriptions #トレーニングデータのキャプションと画像名を紐付ける train_descriptions = load_clean_descriptions('descriptions.txt', train) #バリデーションデータのキャプションと画像名を紐付ける val_descriptions = load_clean_descriptions('descriptions.txt', val) #画像の特徴量を読み込む関数 def load_photo_features(filename, dataset): all_features = load(open(filename, 'rb')) features = {k: all_features[k] for k in dataset}#画像名と特徴量を紐づけてディクショナリに格納 return features #トレーニングデータの特徴量と画像名を紐付ける train_features = load_photo_features('features.pkl', train) #バリデーションデータの特徴量と画像名を紐付ける val_features = load_photo_features('features.pkl', test) #キャプションのディクショナリをリストにする関数 def to_lines(descriptions): all_desc = list() for key in descriptions.keys(): [all_desc.append(d) for d in descriptions[key]] return all_desc #キャプションをKerasのTokenizerで扱うために変換する def create_tokenizer(descriptions): lines = to_lines(descriptions) tokenizer = Tokenizer() tokenizer.fit_on_texts(lines) return tokenizer #tokenizerを準備する tokenizer = create_tokenizer(train_descriptions) vocab_size = len(tokenizer.word_index) + 1 #最も多くの単語を含むキャプションの長さを計算する関数 def max_length(descriptions): lines = to_lines(descriptions) return max(len(d.split()) for d in lines) #最大シーケンス長を計算する max_length = max_length(train_descriptions) #画像と出力単語を紐づける関数 def create_sequences(tokenizer, max_length, descriptions, photos): X1, X2, y = list(), list(), list()#X1が入力画像、X2が入力語、yがX1とX2に対応する出力語 #各画像名でループ for key, desc_list in descriptions.items(): #各画像のキャプションでループ for desc in desc_list: #シーケンスをエンコードする seq = tokenizer.texts_to_sequences([desc])[0] #1つのシーケンスを複数のX、Yペアに分割する for i in range(1, len(seq)): #入力と出力のペアに分割する in_seq, out_seq = seq[:i], seq[i] #行列のサイズを最大の単語数に合わせる in_seq = pad_sequences([in_seq], maxlen=max_length)[0] #出力シーケンス out_seq = to_categorical([out_seq], num_classes=vocab_size)[0] #全てをarrayに格納 X1.append(photos[key][0]) X2.append(in_seq) y.append(out_seq) return array(X1), array(X2), array(y) #トレーニングデータの入力画像、入力語、出力語を紐付ける X1train, X2train, ytrain = create_sequences(tokenizer, max_length, train_descriptions, train_features) #バリデーションデータの入力画像、入力語、出力語を紐付ける X1val, X2val, yval = create_sequences(tokenizer, max_length, val_descriptions, val_features) #モデルを定義する関数 def define_model(vocab_size, max_length): #画像の特徴を入力するレイヤ inputs1 = Input(shape=(4096,)) fe1 = Dropout(0.5)(inputs1) fe2 = Dense(256, activation='relu')(fe1) #文章を入力するレイヤ inputs2 = Input(shape=(max_length,)) se1 = Embedding(vocab_size, 256, mask_zero=True)(inputs2) se2 = Dropout(0.5)(se1) se3 = LSTM(256)(se2) #上の二つの出力を統合する部分 decoder1 = add([fe2, se3]) decoder2 = Dense(256, activation='relu')(decoder1) outputs = Dense(vocab_size, activation='softmax')(decoder2) #モデルの定義.二つを入力にとって一つを出力する形になる model = Model(inputs=[inputs1, inputs2], outputs=outputs) model.compile(loss='categorical_crossentropy', optimizer='adam') return model #モデルの定義 model = define_model(vocab_size, max_length) #コールバックを定義する filepath = 'model-ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5' checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='min') #学習 model.fit([X1train, X2train], ytrain, epochs=10, verbose=2, callbacks=[checkpoint], validation_data=([X1val, X2val], yval)) |
上記のコードは,モデルの構築と学習のコードです.通常,自分の環境で行う場合は最初にパスを指定するだけで,その後生成されるファイルは簡単に参照できるのですが,GoogleColabを使用する場合は少々面倒だと思います.(以前までの記事内でGoogleColabの使い方は一通り説明しているので,GoogleColabを使う場合はそれを参考にしてください.)
テストデータでキャプション生成
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
from numpy import argmax from keras.models import load_model #ディレクトリ内の写真から特徴を抽出する def extract_features_from_image(filename): model = VGG16() model.layers.pop() model = Model(inputs=model.inputs, outputs=model.layers[-1].output) image = load_img(filename, target_size=(224, 224)) image = img_to_array(image) image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2])) image = preprocess_input(image) feature = model.predict(image, verbose=0) return feature photo = extract_features_from_image('path/to/test.image')#テスト画像のパスを指定すること #整数を単語に変換する関数 def word_for_id(integer, tokenizer): for word, index in tokenizer.word_index.items(): if index == integer: return word return None #画像からキャプションを生成する関数 def generate_desc(model, tokenizer, photo, max_length): in_text = 'startseq' for i in range(max_length): sequence = tokenizer.texts_to_sequences([in_text])[0] sequence = pad_sequences([sequence], maxlen=max_length) yhat = model.predict([photo,sequence], verbose=0) yhat = argmax(yhat) word = word_for_id(yhat, tokenizer) if word is None: break in_text += ' ' + word if word == 'endseq': break return in_text model = load_model('model-ep005-loss2.581-val_loss3.135.h5')#最後に出力されたモデルを指定する description = generate_desc(model, tokenizer, photo, max_length) print(description) |
上記のコードは,テストデータを使ってキャプションを生成するコードです.(今回使ったテストデータ以外にも,自前のほかの画像でもすぐにキャプション生成できるので,色々と試してみてください.)
Jupyter notebookなどを使っている場合,学習に引き続いてこのコードを入力すれば,モジュールのインポートは上記のものだけで大丈夫です.しかし,別々のpyファイルとして扱う場合は,モジュールを再度インポートするほか,tokenizerを別途ファイル保存して読み込みする必要があります.