ResNetとは
ResNetはディープラーニングを行うためのモデルの一つであり,2015年のILSVRC(世界的な画像認識コンテスト)で優勝したモデルです.
一般的に,ある程度多層のニューラルネットワークは層が少ないニューラルネットワークよりも精度が高くなりますが,あまりに多くしすぎると勾配消失問題が発生し精度が悪化します.ディープラーニングの学習においては,各層ごとに活性化関数の微分を行い,勾配を計算することで重みを調整しているのですが,層を増やしすぎると微分の積が多くなりすぎて勾配が消えていくという問題があります.
従来のモデルでは各層(Deep path)を通して勾配の計算を行っていますが,ResNetは新たに別の経路(Shortcut Connection)を設けることで,勾配消失を起こしにくくしたモデルです.その結果,ResNetは精度を上げつつ深い階層のネットワークを実現できています.(反面,階層が深いぶん学習時間が長くなりますが…)
さらなる詳しい説明や詳細については,検索したら多くの解説が見つかると思います.
Fine Tuning
実際に自前のデータで学習を行おうとした場合,大量のデータを用意するのは困難な場合があります.しかし,すでに学習済みのモデルをベースにしてそこから学習を行えば,少ないデータでも精度の向上を図ることができます.
Fine Tuningは,すでに学習済みのモデルを用いて再学習を行い,新たなモデルを生成することを指します.よく同列に説明される転移学習(Transfer Learning)は,すでに学習済みのモデルを特徴量の抽出器として使い,別の分類をさせる方法なので,モデル自体を再学習させるFine Tuningとは異なります.
今回は既存のデータセットで学習済みのResNetのFine Tuningを行い,自前のデータセットに対して判定を行うことを目指します.
データセット
事前学習でのデータセット
今回事前学習に使う(使われている)データセットは,ILSVRC2012データセットです.ILSVRC2012データセットは,ImageNetという巨大データセットの中から選ばれた画像データ群で,トレーニングデータ120万枚,バリデーションデータ5万枚,テストデータ10万枚,クラス名1,000種類の巨大なデータセットです. 2015年にResNetが優勝したILSVRCはImageNetのデータを用いて競う大会で,ILSVRC2012データセットはその2012年大会で使われました.
新たに学習させるデータ
新たに学習させるデータとしては,本記事の趣旨的にImageNetの中にないクラスのデータを使いたいところです.とはいえ,このために新たに学習データを揃えるのも面倒くさいです.(本当は記事のタイトル的にも,自前で調達した画像を使いたいんですが…)そこで,今回は料理のデータセットであるFood-101を使います.Food-101には,101種類の料理の画像が,各1000枚ずつ含まれています.Food-101のデータは,検索するか,またはこちらのぺージからダウンロードできます.今回はあくまで例なので,そのうちの一部(apple_pie,french_toast,hot_dog,pizza,sashimi)を使うことにします. これら5種類の料理画像を判別することを目指します.なお,画像は800枚をトレーニング用,200枚をテスト用に用いることにします.
また,今回用いるデータですが,予め以下のような階層のフォルダを構築しておきます.

各画像に対応したフォルダを,train,valの2つのフォルダに分けています.そしてtrainにおける各フォルダにはトレーニング用画像を800枚ずつ(計4000枚),valにおける各フォルダにはテスト用画像を200枚(計1000枚)ずつ入れておきます.
以上のようにすれば,Food-101でなく,自前の画像でも学習ができます.
サンプルコード
以下,サンプルコードです.
今回は用意したファイルをGoogle Driveにアップロードして,Google ColabからGoogle Drive内のファイルにアクセスするやり方でデータを読み込みます.こうすることで,同じデータを開発チーム内でも共有することが可能です.
ここで,ややこしいことにフォルダをそのままGoogle Driveにアップロードしても,それを素直にフォルダとして読み込むのは難しいので,Google Driveにアップロードする前に一旦このフォルダをzipに圧縮して,dataset.zipを作成し,これをGoogle Driveにアップロードします.
ではまず,画像の読み込みに必要なコードを書きます.
|
1 2 3 4 5 |
!pip install -U -q PyDrive from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive from google.colab import auth from oauth2client.client import GoogleCredentials |
2行目と3行目のコードでGoogle DriveにアクセスするためのPyDriveをインポートしていますが,このモジュールは元々Google Colabに標準で入っていません.
そこで,1行目のコードで,pyDriveをGoogle Colabにインストールする必要があります.
インポートできたら,Google Driveにアクセスするための認証を行います.以下のコードで行うことが出来ます.
|
1 2 3 4 |
auth.authenticate_user() gauth = GoogleAuth() gauth.credentials = GoogleCredentials.get_application_default() drive = GoogleDrive(gauth) |
コードを実行したら,以下のようなフォームが出てくると思います.
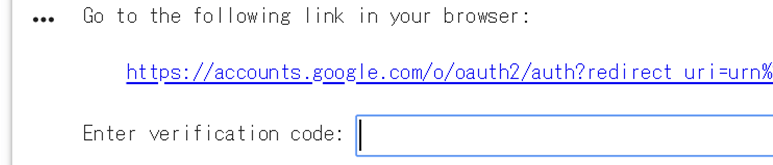
表示されているリンクをクリックして,読み込みたいファイルを保存してあるGoogle Driveアカウントを選択すると,以下のように認証用コードが表示されると思います.

このコードをコピーし,先程のフォームに貼り付けてEnterキーを押します.
特にエラーなどが出なければ,これでデータをアップロードしているGoogle Driveからデータを読み込む準備が完了しました.
ここで,Google Driveから読み込みたいデータについて,「共有可能なリンク」を有効にしておく必要があります.読み込みたいデータをDrive上で右クリックすると,以下のように「共有可能なリンクを取得」を選択できます.
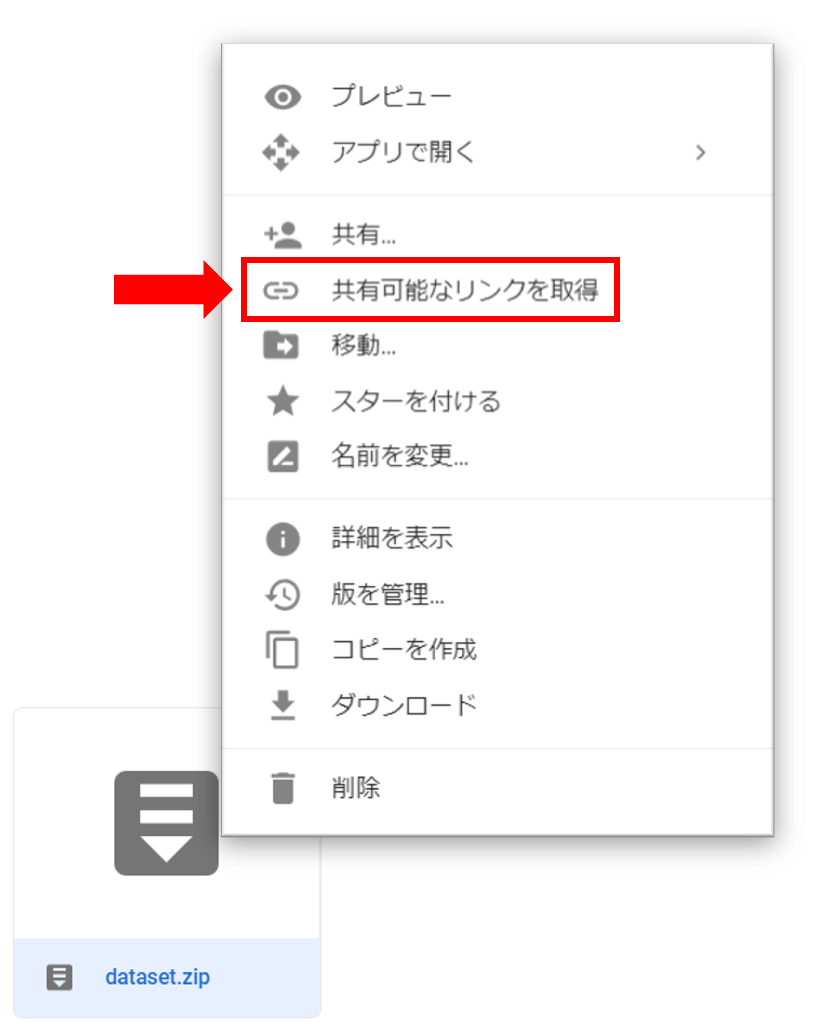
そして,共有設定をオンにすると,「https://drive.google.com/open?id=abcdefg…」のような感じの共有リンクが表示されます.(「共有可能なリンクを取得」をクリックしたら自動的にオンになっているかもしれません.)ここで必要なのが「id=」以降の部分になります.今回示した例でいうとabcdefg…の部分です.ここでは仮に,「id=」以降の部分が「abcdefg」だとしてコードの解説をします.
|
1 2 3 |
id = ' abcdefg ' # 共有リンクで取得したid=以降の部分 downloaded = drive.CreateFile({'id': id}) downloaded.GetContentFile('dataset.zip') |
これで,Google Colab内にzipファイルを読み込むことが出来ました.
つづいて,以下のコードを続けてzipファイルを解凍します.
|
1 |
!unzip dataset.zip |
上のコードを実行すると,解凍されたデータが以下のように表示されると思います.
Archive: dataset.zip
creating: dataset/
creating: dataset/train/
creating: dataset/train/apple_pie/
inflating: dataset/train/apple_pie/101251.jpg
inflating: dataset/train/apple_pie/103801.jpg
~(省略)~
解凍が済んだら,dataset.zipは必要ないです.以下のコードでGoogle Colab上から削除できます.(これはGoogle Colab上から削除するだけで,Google Driveにある元データを削除するわけではないです)
|
1 |
!rm dataset.zip |
以上でGoogle Colabを使う際の,だいぶ面倒くさい作業が完了しました.(自前の環境でやる場合はこれまで書いたコードや,それに伴う作業は必要ないので割と楽)
ようやく本題のコードを書き始めます.まず,トレーニングデータ,テストデータの定義を行います.
|
1 2 3 4 5 6 7 8 9 10 |
classes = ['apple_pie', 'french_toast', 'hot_dog', 'pizza', 'sashimi'] #分類するクラス nb_classes = len(classes) train_data_dir = './dataset/train' validation_data_dir = './dataset/val' nb_train_samples = 4000 nb_validation_samples = 1000 img_width, img_height = 224, 224 |
classesに分類したいクラスを定義しています.今回の場合だと,apple_pie, french_toast, hot_dog, pizza, sashimiです.そして,nb_classesにクラス数を定義しています.4行目,5行目のコードで,読み込むデータのディレクトリを指定しています.7行目,8行目のコードで,トレーニングデータの数,テストデータの数を指定しています.そして,10行目のコードで読み込む画像をすべて同じ大きさにリサイズします.これは最終的に全結合層に特徴マップを読み込ませるためです.今回は224×224にしましたが,あまりに小さいサイズを指定すると画像が縮小されすぎるのでエラーになります.詳細はKerasのドキュメントに書いてあります.
つづいて,読み込んだデータをトレーニングデータ,テストデータとして使えるように定義します.
|
1 2 3 |
from keras.preprocessing.image import ImageDataGenerator train_datagen = ImageDataGenerator(rescale=1.0 / 255, zoom_range=0.2, horizontal_flip=True) validation_datagen = ImageDataGenerator(rescale=1.0 / 255) |
今回のような形式で予めディレクトリを作成しておくと,KerasのImageDataGeneratorでトレーニングデータとテストデータを簡単に定義できます.
ここでは,トレーニングデータに対して,rescale=1.0 / 255, zoom_range=0.2, horizontal_flip=Trueを指定しています.rescaleは,これまで同様に各画素値の0~1への正規化です.後の2つは,トレーニングデータが十分でない場合に画像を水増しするための引数です.zoom_rangeは画像をランダムにズームします.horizontal_flipは,画像をランダムに左右反転させます.テストデータに対しては,水増しする必要が無いので正規化のみです.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
train_generator = train_datagen.flow_from_directory( train_data_dir, target_size=(img_width, img_height), color_mode='rgb', classes=classes, class_mode='categorical', batch_size=16) validation_generator = validation_datagen.flow_from_directory( validation_data_dir, target_size=(img_width, img_height), color_mode='rgb', classes=classes, class_mode='categorical', batch_size=16) |
続いて,.flow_from_directoryで,ディレクトリへのパスを受け取り,拡張/正規化したデータのバッチを生成します.train_generatorにはtrain_data_dirを指定しています.target_sizeは最初に指定した画像サイズで,今回は224×224です.カラー画像なのでcolor_mode=’rgb’,分類するクラスをclassesとして指定,分類は多クラス分類なのでclass_mode=’categorical’を指定しています.学習の際のバッチサイズは16にしました.テストデータについても,同様に設定しています.以上のコードを実行すると,下のような文が出てくると思います.
Using TensorFlow backend.
Found 4000 images belonging to 5 classes.
Found 1000 images belonging to 5 classes.
きちんと,トレーニングデータ4000枚,テストデータ1000枚が定義されているようです.
では,学習を行うモデルを作っていきます.
|
1 2 3 |
from keras.applications.resnet50 import ResNet50 from keras.models import Sequential, Model from keras.layers import Input, Flatten, Dense |
KerasにはImageNetデータセットで学習済みのResNet50(50レイヤのResNet)が最初から用意されているので,インポートするだけで読み込めます.
|
1 2 |
input_tensor = Input(shape=(img_width, img_height, 3)) ResNet50 = ResNet50(include_top=False, weights='imagenet',input_tensor=input_tensor) |
入力画像は224×224のRGB画像なので,これをinput_tensorとして指定しています.今回FineTuningを行うにあたって,出力結果は5クラスの分類にしたいので,全結合層を変更します.そのためにまず,include_top=Falseとすることで,全結合層を除いたResNet50をインポートします.そしてこのとき, weights=’imagenet’とすることで学習済みのResNet50が読み込めます.逆に,weights=Noneとすると,ランダムな初期値から始まります.
つづいて,除去した全結合層の代わりに用いる新たな全結合層を作成します.
|
1 2 3 |
top_model = Sequential() top_model.add(Flatten(input_shape=ResNet50.output_shape[1:])) top_model.add(Dense(nb_classes, activation='softmax')) |
2行目のコードで,ResNet50の出力を1次元化しています.これを出力クラス数が5の全結合層に入力する形で,新たな全結合層を定義します.
|
1 |
model = Model(input=ResNet50.input, output=top_model(ResNet50.output)) |
あとは,全結合層を取り払ったResNet50と,新たに作った全結合層をくっつけてモデルの形づくりは完了です.続いて,学習処理を決めるコンパイルです.
|
1 2 3 4 |
from keras import optimizers model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=1e-3, momentum=0.9), metrics=['accuracy']) |
今回は最適化アルゴリズムに確率的勾配降下法を用いてみました.それでは,これまでに構築したモデルを用いて学習を開始します.
|
1 2 3 4 5 6 |
history = model.fit_generator( train_generator, samples_per_epoch=nb_train_samples, nb_epoch=5, validation_data=validation_generator, nb_val_samples=nb_validation_samples) |
ジェネレータにより生成されたデータで訓練するには,.fit_generatorを使います.samples_per_epochをトレーニングデータ数(4000)にしているので,各エポックで4000個のサンプルが用いられます.バッチサイズを16としたので,1エポックにおけるステップ数は4000/16の,250になります.Fine Tuningでは,すでにある程度重みが定まっているので,エポック数は少なめの5としてみました.ということで今回はEarly stoppingは行なわず,トレーニングデータ全てを訓練に用います.
結果は以下のようになりました.
Epoch 1/5
250/250 [==============================] – 340s 1s/step – loss: 0.6239 – acc: 0.7707 – val_loss: 0.6378 – val_acc: 0.7749
Epoch 2/5
250/250 [==============================] – 326s 1s/step – loss: 0.2571 – acc: 0.9113 – val_loss: 0.5076 – val_acc: 0.8280
Epoch 3/5
250/250 [==============================] – 326s 1s/step – loss: 0.1720 – acc: 0.9415 – val_loss: 0.5026 – val_acc: 0.8349
Epoch 4/5
250/250 [==============================] – 326s 1s/step – loss: 0.1280 – acc: 0.9555 – val_loss: 0.4658 – val_acc: 0.8610
Epoch 5/5
250/250 [==============================] – 326s 1s/step – loss: 0.0843 – acc: 0.9738 – val_loss: 0.4351 – val_acc: 0.8788
最終的に,テストデータに対する正解率が約88%まで上昇しています.
一方,ResNetの読み込み時にweights=Noneとして学習を行った場合(ImageNetの重みを初期値としたFine Tuningを行わなかった場合)の結果を以下に示します.
Epoch 1/5
250/250 [==============================] – 328s 1s/step – loss: 1.8689 – acc: 0.2727 – val_loss: 2.4236 – val_acc: 0.2587
Epoch 2/5
250/250 [==============================] – 315s 1s/step – loss: 1.7146 – acc: 0.3550 – val_loss: 1.5603 – val_acc: 0.3740
Epoch 3/5
250/250 [==============================] – 315s 1s/step – loss: 1.5204 – acc: 0.4150 – val_loss: 1.4414 – val_acc: 0.4109
Epoch 4/5
250/250 [==============================] – 316s 1s/step – loss: 1.3531 – acc: 0.4803 – val_loss: 1.4661 – val_acc: 0.4162
Epoch 5/5
250/250 [==============================] – 315s 1s/step – loss: 1.3628 – acc: 0.4753 – val_loss: 1.2330 – val_acc: 0.5167
ImageNetによる重みから学習をスタートした場合は1エポック目からすでに約77%の正解率が出ていますが,普通に学習させると1エポック目の正解率は約25%となっています.5エポック目でも,約52%までしか上昇していません.このことからもFine Tuningの効果が伺えます.
せっかくなので,今回Fine Tuningで学習したモデルに,テストデータの一部を読み込んで予測確率を出力してみます.今回は下に示すアップルパイの画像を判定させてみます.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from keras.preprocessing import image import numpy as np image_data = 'dataset/val/apple_pie/1005649.jpg' img = image.load_img(image_data, target_size=(img_width, img_height)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = x / 255 pred = model.predict(x)[0] # 予測確率を出力 top = 5 top_indices = pred.argsort()[-top:][::-1] result = [(classes[i], pred[i]) for i in top_indices] print(result) |
上のコードを実行すると,結果は以下のようになりました.
[(‘apple_pie’, 0.9993316), (‘french_toast’, 0.0006522994), (‘pizza’, 8.400712e-06), (‘sashimi’, 5.791974e-06), (‘hot_dog’, 1.8393388e-06)]
高い確率でアップルパイと判定されています.
コード全文
以下に,今回のコード全文を示します.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
!pip install -U -q PyDrive from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive from google.colab import auth from oauth2client.client import GoogleCredentials auth.authenticate_user() gauth = GoogleAuth() gauth.credentials = GoogleCredentials.get_application_default() drive = GoogleDrive(gauth) id = ' abcdefg ' # 共有リンクで取得したid=以降の部分.左のコードは一例. downloaded = drive.CreateFile({'id': id}) downloaded.GetContentFile('dataset.zip') !unzip dataset.zip !rm dataset.zip |
以上のコードはGoogle Colabでデータファイルを読み込ませるために行うコード.自前の環境で行う場合は不要.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
from keras.preprocessing.image import ImageDataGenerator from keras.applications.resnet50 import ResNet50 from keras.models import Sequential, Model from keras.layers import Input, Flatten, Dense from keras import optimizers classes = ['apple_pie', 'french_toast', 'hot_dog', 'pizza', 'sashimi'] #分類するクラス nb_classes = len(classes) train_data_dir = './dataset/train' validation_data_dir = './dataset/val' nb_train_samples = 4000 nb_validation_samples = 1000 img_width, img_height = 224, 224 train_datagen = ImageDataGenerator(rescale=1.0 / 255, zoom_range=0.2, horizontal_flip=True) validation_datagen = ImageDataGenerator(rescale=1.0 / 255) train_generator = train_datagen.flow_from_directory( train_data_dir, target_size=(img_width, img_height), color_mode='rgb', classes=classes, class_mode='categorical', batch_size=16) validation_generator = validation_datagen.flow_from_directory( validation_data_dir, target_size=(img_width, img_height), color_mode='rgb', classes=classes, class_mode='categorical', batch_size=16) input_tensor = Input(shape=(img_width, img_height, 3)) ResNet50 = ResNet50(include_top=False, weights='imagenet',input_tensor=input_tensor) top_model = Sequential() top_model.add(Flatten(input_shape=ResNet50.output_shape[1:])) top_model.add(Dense(nb_classes, activation='softmax')) model = Model(input=ResNet50.input, output=top_model(ResNet50.output)) model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=1e-3, momentum=0.9), metrics=['accuracy']) history = model.fit_generator( train_generator, samples_per_epoch=nb_train_samples, nb_epoch=5, validation_data=validation_generator, nb_val_samples=nb_validation_samples) |
↓テストデータの,./apple_pie/1005649.jpgをテストしてみた場合のコード.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from keras.preprocessing import image import numpy as np image_data = 'dataset/val/apple_pie/1005649.jpg' img = image.load_img(image_data, target_size=(img_width, img_height)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = x / 255 pred = model.predict(x)[0] # 予測確率を出力 top = 5 top_indices = pred.argsort()[-top:][::-1] result = [(classes[i], pred[i]) for i in top_indices] print(result) |