CNNとは
CNNとは(導入)
画像認識などの複雑な問題を簡単なニューラルネットワークで解くのは限界があります.そこで,その発展形であるCNN(Convolution Neural Network)を使います.また,ディープラーニング(深層学習)という場合,レイヤの数が多いニューラルネットワークによる学習のことを指す場合もありますが,一般的にはCNNを使った学習のことを指す場合が多いです.(他にも色々ありますが…)
ニューラルネットワークで画像認識を行おうとすると,画像の各画素値が各入力値として用いられることになりますが,対象物の位置が少しずれたり,形が変化したりするだけで入力値が大きく変わってしまいます.例えば以下の図のように,【2】という文字が書かれた画像を認識しようとしたとします.
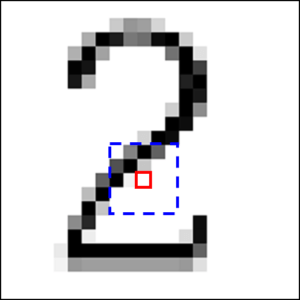
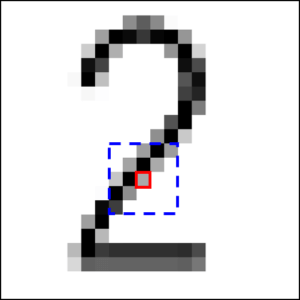

いずれも私達の目では2であることがわかりますが,各画素の赤枠部分は,どれも同じ位置にもかかわらず,色が異なっています.ですが,青い点線で囲まれた部分を見てみると,どれもなんとなく右上から左下に向かって黒い画素が並んでいるように見えます.つまり,個別の画素ではなく,ある程度広い領域をまとめて入力として使えば,より精度の高い判定ができそうだ,というのがCNNの考え方です.
畳み込み層
ある程度広い領域を入力するために用いるのが,フィルタと呼ばれる小領域(上の図の青枠のようなもの)です.例えば,【2】という画像に対して,「右上から左下に向かう黒い画素の集まり」のフィルタを用意して,これを画像の端から端まで走らせ,場所ごとの一致度を記録します.おそらく画像の真ん中や左上あたりでは,用意したフィルタとの一致度が高くなるでしょう.


フィルタおよびフィルタの重ね合わせのイメージ.
畳み込み層では,この一致度(特徴マップ)を出力する
この,場所ごとの一致度の情報を出力する層が畳み込み層で,上記の処理を畳み込みといいます.なお,今回は例として「右上から左下に向かう黒い画素の集まり」のフィルタの話をしましたが,実際には様々な種類のフィルタを用意して,フィルタごとに畳み込みを行うので,大量の畳み込み結果(特徴マップ)が出力されます.また,各フィルタは判定したい対象に適したものが学習の結果から生成されます.
プーリング層
畳み込み層から出力された特徴マップは,それでも入力画像によってばらつきがあります.そこで,特徴マップを大まかなウィンドウに区切り,各ウィンドウの中での最大値を代表値として画像を縮小します(Max-poolingの場合).これにより,ばらつきの影響を低減させます.
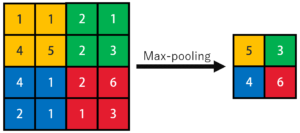
この,特徴マップを縮小する工程をプーリングといい,プーリングが行われる層をプーリング層といいます.また,プーリングを行うとデータの個数が区切ったウィンドウの個数に縮小されるのが分かると思います.よって以降の計算量が一気に少なくなるといった,もう一つの大きな利点があります.
CNNとは(まとめ)
これまでに説明した畳み込み層とプーリング層,そして活性化関数の層を幾重にも重ねることで構築されているのがCNNです.なお,最終的には特徴マップではなく判定結果を出力したいので,CNNでは終盤に全結合層を設け,特徴マップから判定結果を導きます.以上がCNNの基礎事項になります.では,実際にデータを使ってその性能を確かめてみましょう.
データセット
今回は,CIFAR-10(サイファーテン)というデータセットを使います.CIFAR-10はairplane, automobile, bird, cat, deer, dog, frog, horse, ship, truckの10クラスにラベル分けされた32×32画素のカラー画像データで,50000枚のトレーニングデータと10000枚のテストデータが用意されています.以下の画像はCIFAR-10の中身の一例です.

サンプルコード
以下,サンプルコードです.Kerasを使ってCNNを構築し,CIFAR-10のデータを判定します.
|
1 2 |
import keras from keras.datasets import cifar10 |
MNISTと同様に,CIFAR-10もKerasに最初から用意されているので,インポートするだけで読み込めます.自分のデータで学習したかったら,前回,MNISTの結果確認で行ったような手順でフォルダから読み込むことになります.
|
1 |
(X_train, y_train), (X_test, y_test) = cifar10.load_data() |
そしてMNISTと同様にCIFAR-10もトレーニングデータとテストデータに分割します.
前回のニューラルネットワーク構築の際には,ここで画像データを1次元配列に変換していましたが,畳み込みとプーリングを行わなければならないので,この変換はここでは行いません.これは畳み込みとプーリングを終えて全結合層に入力する段階で行います.
|
1 2 3 4 |
X_train = X_train.astype('float32') X_test = X_test.astype('float32') X_train /= 255.0 X_test /= 255.0 |
各画素値を0~1の間に収まるように変換します.今回はカラー画像なので,RGBの値それぞれにこの処理が適用されています.
|
1 2 |
y_train = keras.utils.to_categorical(y_train, 10) y_test = keras.utils.to_categorical(y_test, 10) |
そしてラベルデータを2値クラスの配列に変換しています.これも10クラスなので前回と同様.
ではCNNを構築します.ちょっと長いです.
|
1 2 3 |
from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Convolution2D, MaxPooling2D |
前回と違い, Flatten,Convolution2D,MaxPooling2Dをインポートします.
Flattenは平滑化層で,畳み込みとプーリングが終わったあと全結合層に入力する際に特徴マップを1次元配列に変換します.Convolution2DとMaxPooling2Dはそれぞれ畳み込み層とプーリング層です.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
model = Sequential() model.add(Convolution2D(32, 3, 3, border_mode='same', activation='relu', input_shape=X_train.shape[1:])) model.add(Convolution2D(32, 3, 3, activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Convolution2D(64, 3, 3, activation='relu', border_mode='same')) model.add(Convolution2D(64, 3, 3, activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation= 'softmax')) |
今回構築したモデルは,入力→畳み込み→畳み込み→プーリング→畳み込み→畳み込み→プーリング→全結合層→全結合層(出力)といった流れになっています.プーリング層と全結合層でドロップアウトを行っています.
最初の畳み込み層における,32, 3, 3はそれぞれフィルタの数,フィルタサイズ,フィルタを一度に動かす幅(ストライド)です.border_mode=’same’を指定することによって,画像の周囲にパディングを施して畳み込み後も画像の大きさが変わらないようにします.以下の図を見るとイメージしやすいかと思います.
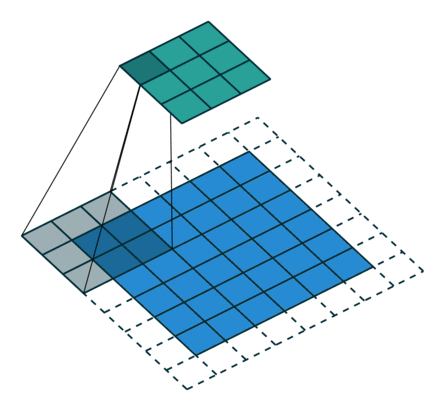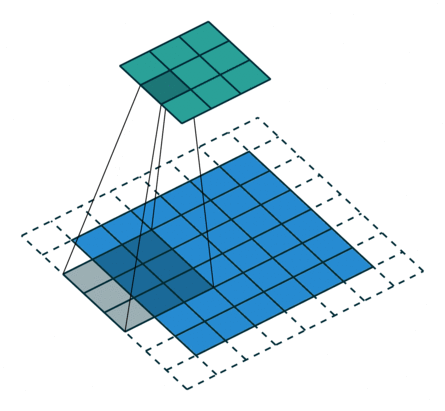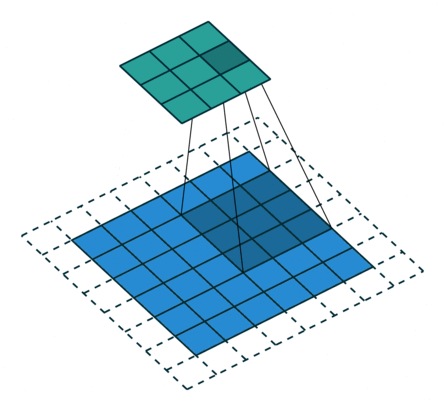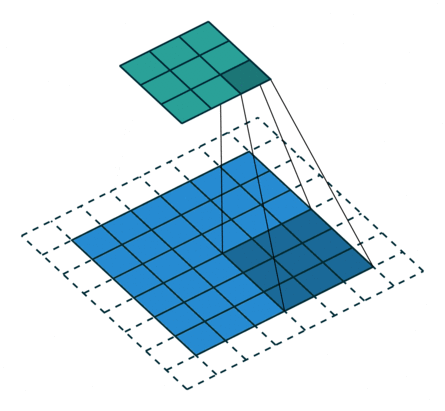
下の画像が入力,上の画像が出力
(vdumoulin/conv_arithmetic – GitHub)
そしてinput_shape=X_train.shape[1:]は入力画像の形状です.今回は(32,32,3)になります.
プーリング層におけるpool_size=(2, 2)は,プーリングしてダウンスケールする大きさです.今回の場合,一度のプーリングで画像の大きさが縦横半分になります.また,プーリング結果にドロップアウトを適用しています.
以上が今回構築したCNNの構造です.続いて,学習処理を決めるコンパイルです.
|
1 2 3 |
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) |
今回は最適化アルゴリズムにAdamを用いました.それでは,これまでに構築したモデルを用いて学習を開始します.
|
1 2 3 4 5 6 7 8 |
from keras.callbacks import EarlyStopping history = model.fit(X_train, y_train, batch_size=100, epochs=30, verbose=1, validation_split=0.1, callbacks=[EarlyStopping()]) |
エポック数が多すぎると過学習する可能性があるので,今回はいい感じのところで学習を打ち切れるようにします(Early stopping).
そのために,callbacks = [EarlyStopping()]と設定しておきます.こうすることで,エポック数増加による過学習を起こす前に,学習をストップさせることが出来ます.
Early stoppingを行うために,トレーニングデータの一部をバリデーションデータとして設定します.validation_split = 0.1とすることでトレーニングデータのうち最後の10%をバリデーションデータとして用いることができます.(なので実際にトレーニングに使われるのはトレーニングデータの90%です.)
また,このようにするとトレーニングデータ全てを訓練に用いることはできなくなるので,適切なエポック数が設定できていればEarly stoppingは行わなくてもいいかもしれません.
最後にテストデータを用いて学習精度を確認するためのコードを入力します.
|
1 2 3 |
score = model.evaluate(X_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) |
結果は以下のようになりました.CNNはCPUで計算すると時間がいくらあっても足りないので,Google ColabのGPU機能を使って計算しました.
Epoch 1/30
45000/45000 [==============================] – 15s 339us/step – loss: 1.6045 – acc: 0.4111 – val_loss: 1.2246 – val_acc: 0.5628
~(省略)~
Epoch 12/30
45000/45000 [==============================] – 13s 281us/step – loss: 0.5692 – acc: 0.7988 – val_loss: 0.6251 – val_acc: 0.7868
Test loss: 0.6488395797729493
Test accuracy: 0.7786
Early stoppingを用いた結果,最初に指定した30エポックに達する前に終了しています.つまりこれ以上学習を進めても精度が上がらないと判断されたということです.そして,テストデータに対する精度は約78%でした.
ネットで検索すれば,VGG-16やGoogleNet,ResNetといった,すでに高い成果を出しているモデルも公開されているので,これらを用いればさらに精度は向上すると思います.
コード全文(KerasでCNN)
今回紹介したコード全文を以下に示します.関数などの呼び出し文はコードの先頭にまとめています.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
import keras from keras.datasets import cifar10 from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Convolution2D, MaxPooling2D from keras.callbacks import EarlyStopping (X_train, y_train), (X_test, y_test) = cifar10.load_data() X_train = X_train.astype('float32') X_test = X_test.astype('float32') X_train /= 255.0 X_test /= 255.0 y_train = keras.utils.to_categorical(y_train, 10) y_test = keras.utils.to_categorical(y_test, 10) model = Sequential() model.add(Convolution2D(32, 3, 3, border_mode='same', activation='relu', input_shape=X_train.shape[1:])) model.add(Convolution2D(32, 3, 3, activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Convolution2D(64, 3, 3, activation='relu', border_mode='same')) model.add(Convolution2D(64, 3, 3, activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation= 'softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) history = model.fit(X_train, y_train, batch_size=100, epochs=30, verbose=1, validation_split=0.1, callbacks=[EarlyStopping()]) score = model.evaluate(X_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) |


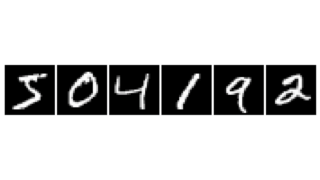


{kind=link}