ニューラルネットワークとは
ニューラルネットワークは,近年流行りのディープラーニングの基礎となる手法です.下図のようにいくつかのニューロンというものを結合してネットワークを構成したものをニューラルネットワークといい,入力した値に応じて何らかの出力が得られます.

各ニューロンに何らかの数値が入力されると,それに応じて新たな数値が次の層の各ニューロンに入力されます.最終的に出力層のニューロンが出力した数値が,そのニューラルネットワークが導いた答えとなります.
もう少し詳しく説明すると,各ニューロンに入力された値は,その時点でまず活性化関数とよばれる関数に代入され,解を出力します.活性化関数にも色々あるのですが,例えばReLU関数(ランプ関数)であれば,0未満の数値が入力されると0を,0以上の数値が入力されるとその値を出力します.
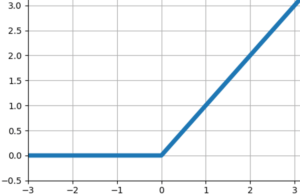
また,活性化関数を通して出力された値を次のニューロンに渡すときに,何らかの定数を乗じてから渡します.これは重みなどと言われます.そして,活性化関数と重みがきちんと設定されていれば,最初の入力に応じて,それに応じた出力が得られるという仕組みです.
重みの設定においては,予め正解が分かっているデータを用意して,出力値と正解値を比較し,その誤差に応じて各重みが調整されます(バックプロパゲーション).
以上がニューラルネットワークの簡単な説明です.それでは実際にニューラルネットワークを用いた分類を,コードを見ながら確認していきます.
データの説明
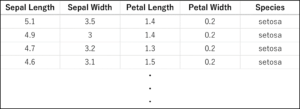
前回に引き続き,機械学習用データセットとしてよく使われるアヤメのデータセットを用います.再掲になりますが,以下の表にその一部を示します.150件のデータがSetosa, Versicolor, Virginicaの3品種に分類されており,それぞれ,Sepal Length(がく片の長さ), Sepal Width(がく片の幅), Petal Length(花びらの長さ), Petal Width(花びらの幅)の4つの特徴量を有しています.これらの特徴量から,品種を推定・分類することを目指します.
サンプルコード
以下,サンプルコードです.基本的な内容のみ触れるため,全体の流れは前回示した決定木による分類とほとんど同じです.単に使う道具が変わった結果としてコードがほんの少し変わるだけなので,困ることはないと思います.また,ページ下部にコード全文を再度載せておきます.
|
1 2 3 |
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.neural_network import MLPClassifier |
Pythonの機械学習用ライブラリのひとつであるscikit-learnを用いて,ニューラルネットワークによる分類を行います.scikit-learnにはすでにアヤメのデータセットが用意されています.1行目のコードでアヤメのデータセットをインポートしています.データセットのうち,いくつかは学習に用いて,残りは精度の評価に用います.2行目のコードでデータセットを分けるための関数をインポートしています.3行目のコードは,scikit-learnでニューラルネットワークを扱うための関数をインポートしています.
|
1 2 3 |
iris = load_iris() X = iris.data y = iris.target |
まず,変数irisに,インポートしたアヤメのデータセットを代入します.さらに,代入したデータの中から,特徴量を示すデータiris.dataを変数Xに代入します.また,品種を示すデータiris.targetを変数yに代入します.ここで,変数X,yの中身を確認してみます.
|
1 2 |
print (X[0:5,:]) print(y) |
Xは中身が多いので最初の5行だけ表示します.実行すると,以下のような結果が得られます.
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2][5. 3.6 1.4 0.2]]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
Xの中身は,最初に示した特徴量の表と同じ値になっていることがわかります.yの中身は0,1,2が表示されています.それぞれの数値がSetosa, Versicolor, Virginicaの品種を表しています.
|
1 |
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) |
test_sizeの指定により,Xとyの中身を,学習用7割,テスト用3割に分けます.random_stateはデータを分割する際の乱数のシード値です.
|
1 2 |
clf = MLPClassifier(max_iter=10000) clf.fit(X_train, y_train) |
clfに,今回学習に用いるニューラルネットワークを定義します.ここで,一回の学習を行う際に,一気にすべてのデータを使わず,一部をランダムに使って学習を行い,これが何回も繰り返されます.これを何回繰り返すのかをmax_iterで定義しています.この値が小さすぎると解が収束する前に学習が終わってしまいますし,大きすぎるとトレーニングデータに過剰に適合した過学習に陥る場合があるので注意が必要です.また,このときに引数としてactivationを設定することで活性化関数を指定できます.デフォルトではReLU関数(ランプ関数)になっています.
つづいて,clf.fitで学習を開始することで,トレーニングデータに適した重みになるように調整が行われます.
|
1 |
print (clf.score(X_test, y_test)) |
学習したニューラルネットワークを用いて,テストデータの判定を行います.判定した結果をprint関数で表示した結果が以下のようになります.
0.9777777777777777
だいたい98%の正解率であることがわかります.ここで,アヤメのデータセットに対して全体的にどの程度の正解率を出すことができるのか確認するため,K分割交差検証を行います.今回はK=10として,データを10分割してそれぞれの結果を見てみます.
|
1 2 3 4 5 6 7 8 |
from sklearn.model_selection import StratifiedKFold, cross_val_score import numpy as np stratifiedkfold = StratifiedKFold(n_splits=10) #K=10分割 scores = cross_val_score(clf, X, y, cv=stratifiedkfold) print('Cross-Validation scores: {}'.format(scores)) # 各分割におけるスコア print('Average score: {}'.format(np.mean(scores))) # スコアの平均値 |
結果は以下のようになりました.
Cross-Validation scores: [1. 1. 1. 1. 0.86666667 1. 0.93333333 1. 1. 1. ]
Average score: 0.9800000000000001
交差検証の結果からしても,平均して98%の正解率を出すことができています.
コード全文(ニューラルネットワーク)
このページで紹介したニューラルネットワークのコード全文を載せておきます.関数などの呼び出しはコードの先頭にまとめ,途中で行った確認用のprint文などは省いています.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.neural_network import MLPClassifier from sklearn.model_selection import StratifiedKFold, cross_val_score import numpy as np iris = load_iris() X = iris.data y = iris.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) clf = MLPClassifier(max_iter=10000) clf.fit(X_train, y_train) print (clf.score(X_test, y_test)) #正解率の表示 #K分割交差検証 stratifiedkfold = StratifiedKFold(n_splits=10) #K=10分割 scores = cross_val_score(clf, X, y, cv=stratifiedkfold) print('Cross-Validation scores: {}'.format(scores)) # 各分割におけるスコア print('Average score: {}'.format(np.mean(scores))) # スコアの平均値 |